Point Bridge: 3D Representations for Cross Domain Policy Learning
Abstract
Robot foundation models are starting to realize some of the promise of developing generalist robotic agents, but progress remains bottlenecked by the availability of large-scale real-world robotic manipulation datasets. Simulation and synthetic data generation are a promising alternative to address the need for data, but the utility of synthetic data for training visuomotor policies still remains limited due to the visual domain gap between the two domains. In this work, we introduce POINT BRIDGE, a framework that uses unified domain-agnostic point-based representations to unlock the potential of synthetic simulation datasets and enable zero-shot sim-to-real policy transfer without explicit visual or object-level alignment across domains. Point Bridge combines automated point-based representation extraction via Vision-Language Models (VLMs), transformer-based policy learning, and inference-time pipelines that balance accuracy and computational efficiency to establish a system that can train capable real-world manipulation agents with purely synthetic data. Point Bridge can further benefit from co-training on small sets of real-world demonstrations, training high-quality manipulation agents that substantially outperform prior vision-based sim-and-real co-training approaches. POINT BRIDGE yields improvements of up to 44% on zero-shot sim-to-real transfer and up to 66% when co-trained with a small amount of real data. Point Bridge also facilitates multi-task learning.
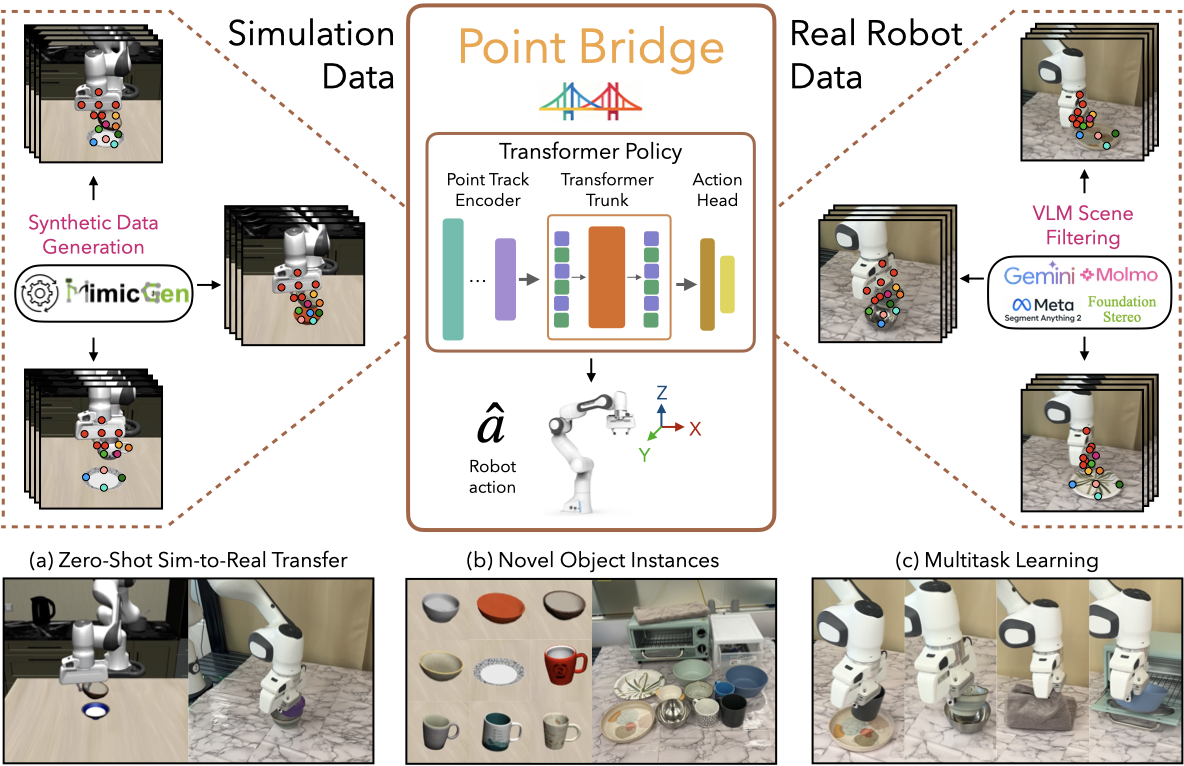
Zero-shot Sim-to-Real Transfer
We evaluate Point Bridge for zero-shot sim-to-real transfer on 3 simulated tasks. We observe that Point Bridge’s scene-filtering strategy produces domain-invariant representations, outperforming the strongest baseline by 39% in single-task transfer and 44% in multitask transfer. We provide videos of successful rollouts below (all played at 2X speed).
Task: Object: Trajectory:
Point Bridge on Soft and Articulated Objects
We evaluate single-task Point Bridge policies on three tasks involving soft objects (towel) and articulated objects (drawer, oven). Overall, Point Bridge achieves an 85% success rate across these tasks, highlighting its effectiveness beyond rigid-object manipulation. We provide videos of successful rollouts below (all played at 2X speed).
Task: Trajectory:
Point Bridge on held-out objects
We evaluate multi-task-task sim-real co-trained Point Bridge policies on a set of held-out objects. Overall, Point Bridge achieves an 97% success rate across these tasks, highlighting its effectiveness in generalizing to unseen objects. We provide videos of successful rollouts below (all played at 2X speed).
Task: Object: Trajectory:
Point Bridge in the presence of background distractors
To evaluate the robustness of our scene filtering pipeline, we evaluate the zero-shot single-task sim-to-real transfer performance of Point Bridge with background distractors. Overall, Point Bridge, which incorporates scene filtering, maintains performance on par with the distractor-free scenario and exhibits strong robustness to background clutter. We provide videos of successful rollouts below (all played at 2X speed).
Task: Trajectory:
Bibtex
@article{haldar2026pointbridge,
title={Point Bridge: 3D Representations for Cross Domain Policy Learning},
author={Haldar, Siddhant and Johannsmeier, Lars and Pinto, Lerrel and Gupta, Abhishek and Fox, Dieter and Narang, Yashraj and Mandlekar, Ajay},
journal={arXiv preprint arXiv:2601.16212},
year={2026}
}